
LightSecAgg: a Lightweight and Versatile Design for Secure Aggregation in Federated Learning
这篇文章有更详细的笔记,见:https://www.yuque.com/u32959745/rp74hp/vtrsd91dg72eu88v
摘要
安全模型聚合是联合学习(FL)的关键组成部分,旨在保护每个用户单个模型的隐私,同时允许其全局聚合。它可以应用于任何基于聚合的、用于训练global或personalized模型FL方法。模型聚合还需要抵抗FL系统中可能的用户dropouts,这使其设计更加复杂。最先进的安全聚合协议rely on secret sharing of the random-seeds used for mask generations at the users to enable the reconstruction and cancellation of those belonging to the dropped users。但是,这种方法的复杂性随着dropped用户的数量而大大增长。
我们提出了一种名为LightSecAgg的新方法,以通过将设计从“random-seed reconstruction of the dropped users”更改为“one-shot aggregate-mask reconstruction of the active users via mask encoding/decoding”来克服这种瓶颈。我们表明,LightSecAgg具有与最先进的协议相同的privacy和dropout-resiliency,同时大大降低了the overhead for resiliency against dropped users。我们还证明,与现有方案不同,可以应用LightSecAgg在异步FL设置中确保聚合。
此外,我们通过实现model training和on-device encoding之间的computational overlapping,并提高了同时接收和发送chunked masks的速度,从而为可扩展实现提供了模块化系统设计并优化了设备并行化。我们通过广泛的实验评估LightSecAgg在各种数据集(MNIST,FEMNIST,CIFAR,CIFAR-10,GLD-23K)上的训练不同模型(逻辑回归,浅CNN,MobileNetV3和ExtricNet-B0)评估,并具有大量的使用者。并证明LightSecAgg大大减少了总训练时间。
成果叫做:LightSecAgg
核心思想:one-shot aggregate-mask reconstruction of the active users via mask encoding/decoding
1. INTRODUCTION
最先进的安全聚合协议基本上依赖两个主要原则:
- 用户之间会使用pairwise的random-seed agreement来生成masks,用masks去hide用户模型。(有一个前提:模型是additive结构的,可以在server端相加的时候抵消掉masks)
- 对random-seed进行的秘密共享能够重构和抵消属于dropped用户的masks。
这种方法的主要缺点是,当dropped用户增加时,服务器上的mask重构数量大幅增加。这就是主要的computational bottleneck。
对此问题,分析一下现有的几种SA方法的表现:
- SECAGG:在(Bonawitz等,2017)中提出的Secagg协议的执行时间受到服务器上的掩模重建的限制(Bonawitz等,2019b)
- Secagg+:(Bell等,2020)是一种改进的Secagg版本,通过用稀疏的随机图替换Secagg的完整通信图来减少服务器上的开销所有用户对。但是,随着越来越多的用户drop,secagg+中的掩模重建数量仍然会增加,最终限制了FL系统的可扩展性。
- 还有其他几种方法,例如(So等,2021d; Kadhe等,2020),以减轻这种瓶颈,但是它们会increase round/communication complexity或者compromise the dropout and privacy guarantees。
Contributions.
我们通过将设计重点从“pairwise random-seed reconstruction of the dropped users”转变为“one-shot aggregate-mask reconstruction of the surviving users”,提出了对FL中安全模型聚合的新观点。
我们开发了一个名为LightseCagg的新协议,该协议提供了与最先进的协议同等程度的privacy和dropout-resiliency guarantees,同时大大降低了聚合(因此运行时)的复杂性。
如图1所示,LightseCagg的主要思想是,每个用户都使用本地生成的随机掩码保护其本地模型。然后,将此掩码编码并与其他用户共享,以使任何足够大的surviving用户的aggregate-mask可以直接在服务器上重建。
与先前的方案形成鲜明对比的是,在这种方法中,服务器只需要在recover阶段重建一个掩码,而与掉落用户的数量无关。
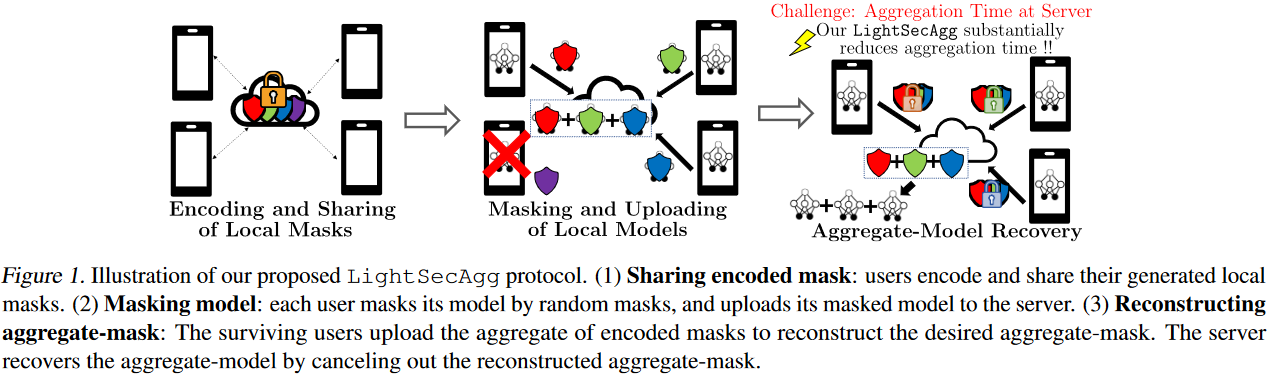
我们进一步提出了系统级优化方法:每个用户可以通过多线程处理并行地进行随机掩码的产生和本地模型的计算这两个操作。
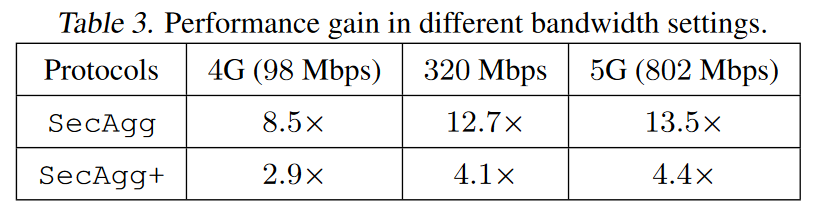
在用户在现实的带宽设置中,对于secagg的性能增益为8.5×-12.7×,对于secagg+的2.9×-4.4×。因此,与基线相比,LightseCagg甚至可以在高分辨率图像数据集上survive并加速对大型深神经网络模型的训练。总运行时间的细分进一步证实,primary gain在于LightseCagg提供的服务器的复杂性降低,尤其是当用户数量较大时。
Related Work
除了在(Bonawitz等,2017; Bell等,2020)中提出的SECAGG之外,还有其他旨在使SA更有效的作品
- Turboagg(So等,2021d)利用循环通信拓扑来减少开销的交流,但它会带来额外的round复杂性,并提供了比Secagg更弱的隐私保证,因为它可以保证平均意义上的模型隐私,而不是在最糟糕的情况下。
- FastSecagg(Kadhe等,2020)通过使用Fast Fourier Transform多秘密共享来减少每个用户的开销,但与其他最先进的协议相比,它提供了较低的隐私和dropout guarantees。
- (Zhao&Sun,2021)也采用了one-shot reconstruction of the aggregate-mask的想法,其中,与每个用户dropout pattern相对应的aggregated masks是由可信赖的第三方在模型聚合之前编码和分配给用户的。
- LightseCagg相对于(Zhao&Sun,2021)工作的主要优势是:
- 不需要值得信赖的第三方;
- 每个用户的随机性产生要少得多,存储成本要小得多。
- 此外,在FL实验中,(Zhao&Sun,2021)也缺乏系统级的性能评估
2. PROBLEM SETTING
FL的SA协议需要有的几个关键要素:
Threat model and privacy guarantee
我们考虑了一个威胁模型,用户和服务器诚实但好奇。
我们假设最多可以T个(out of N)用户可以相互勾结,以及与服务器相互勾结,以推断其他用户的本地模型。
SA协议必须保证,即使T个用户彼此合作,除aggregate-model之外的任何东西都无法被学习到。
我们考虑在strong的信息论意义上考虑隐私泄漏。这就要求对用户的每个子集$$\mathcal{T} \subseteq [N]$$(大小最多为T),我们必须使得:(共同信息没有交集:question:)
$$
I\left(\left{\mathbf{x}{i}\right}{i \in[N]} ; \mathbf{Y} \mid \sum_{i \in \mathcal{U}} \mathbf{x}{i}, \mathbf{Z}{\mathcal{T}}\right)=0
$$
其中Y是服务器上信息的collection,而$$Z_{\mathcal{T}}$$是$$\mathcal{T}$$中用户的信息collection。
Dropout-resiliency guarantee
我们假设最多有D个用户在执行协议期间drop,即,潜在的辍学后至少有N-D个surviving用户。
该协议必须确保服务器可以正确恢复surviving用户的aggregated models。
Applicability to asynchronous FL
我们旨在设计一种适用于同步和异步FL的多功能安全聚合协议
Goal.
我们旨在设计一种:
- 高效且可扩展的安全聚合协议
- 该协议同时实现了强大的privacy 和dropout-resiliency guarantees
- 相对用户的数量N进行线性扩展,例如,同时实现隐私保证T=N/2和dropout保证D=N/2-1
- 此外,该协议应与同步和异步FL兼容
3. OVERVIEW OF BASELINE PROTOCOLS: SECAGG AND SECAGG+
我们首先将最新的安全汇总协议Secagg(Bonawitz等,2017)和Secagg+(Bell等,2020)视为我们的基线。本质上,Secagg和Secagg+要求每个用户在聚合之前使用random keys掩盖其本地模型。
SECAGG
agree on a pairwise random seed
在Secagg中,单个模型的隐私受到pairwise random masking的保护。通过密钥协商协议(例如Diffie-Hellman(Diffie&Hellman,1976)),每对用户i,j∈[N] agree on a pairwise random seed:
$$
a_{i,j}=Key.Agree(sk_i,pk_j)=Key.Agree(sk_j,pk_i)
$$
其中$$sk_i$$和$$pk_i$$分别是用户i的私钥和公钥。
creates a private random seed
此外,用户i会创建一个私人随机种子bi,以防止如果用户i仅delay而不是drop时可能会发生的隐私漏洞——在这种情况下,pairwise masks是不足以保护隐私的。
mask model and send to server
然后用户i∈[N]然后将其模型xi mask为:
$$
\tilde{\mathbf{x}}{i}=\mathbf{x}{i}+\operatorname{PRG}\left(b_{i}\right)+\sum_{j: i<j} \operatorname{PRG}\left(a_{i, j}\right)- \sum_{j: i>j} \operatorname{PRG}\left(a_{j, i}\right)
$$
其中prg是伪随机生成器,并将其发送到服务器。
secret share
最后,用户i通过Shamir秘密共享与其他用户秘密地共享其私人种子bi以及私钥ski(Yao,1982)。
server collect/reconstruct/aggregate
从the subset of users who survived the previous stage中,服务器可以收集:属于drop用户的shares of the private key,或者,属于surviving用户的shares of the private seed(但不能两者同时获取)。
使用收集到的shares,服务器重建每个surviving用户的私人种子,以及每个drop用户的pairwise种子。服务器然后计算聚合模型如下:
$$
\begin{aligned}
\sum_{i \in \mathcal{U}} \mathbf{x}{i} &=\sum{i \in \mathcal{U}}\left(\tilde{\mathbf{x}}{i}-\operatorname{PRG}\left(b{i}\right)\right) \
&+\sum_{i \in \mathcal{D}}\left(\sum_{j: i<j} \operatorname{PRG}\left(a_{i, j}\right)-\sum_{j: i>j} \operatorname{PRG}\left(a_{j, i}\right)\right)
\end{aligned}
$$
U和D分别代表surviving和dropped用户的集合。
Secagg保护模型隐私免受T个colluding用户的侵害,并且在N-D>T的情况下,对于D个用户dropout是robust的。
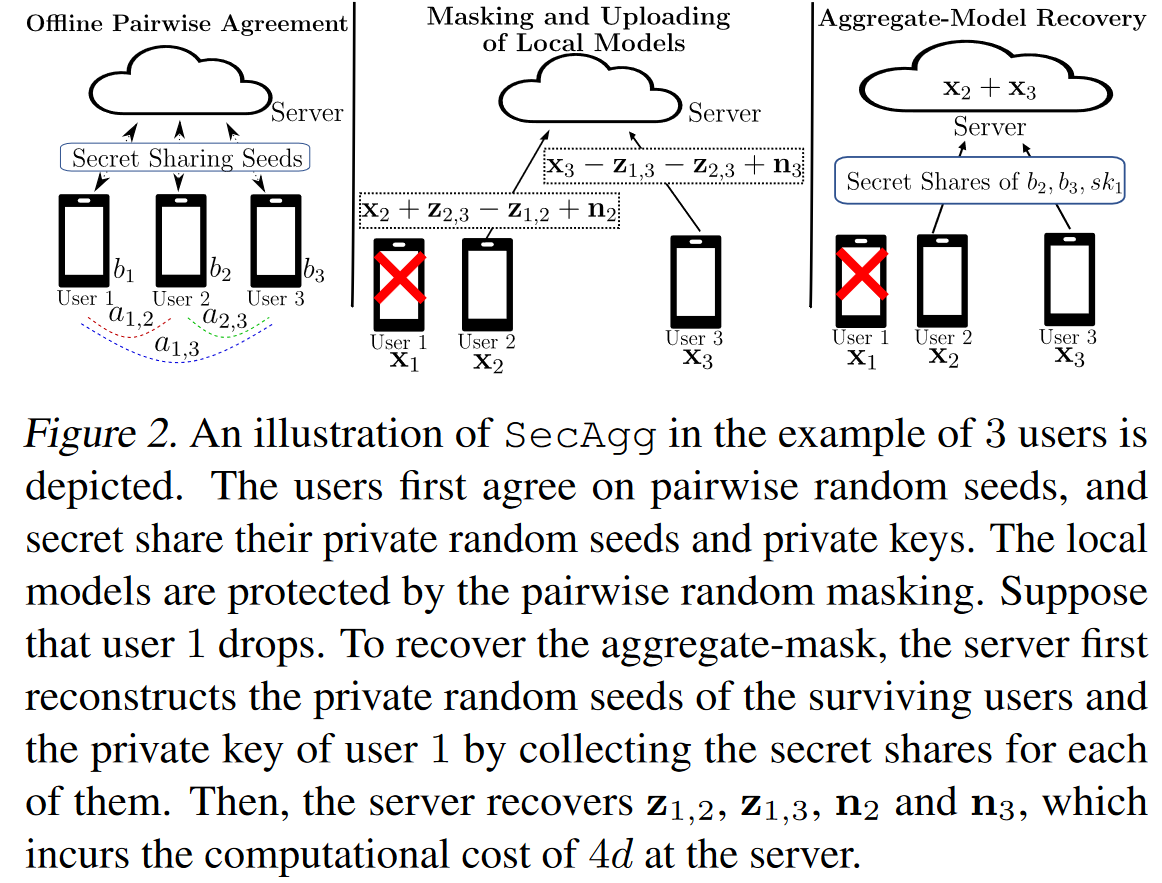
SECAGG的简单实例
Offline pairwise agreement.
用户1和用户2 agree on pairwise随机种子a1,2。
用户1和用户3 agree on pairwise随机种子a1,3。
用户2和用户3 agree on pairwise随机种子a2,3。
另外,用户i∈{1、2、3}创建一个私有的随机种子bi。
然后,用户i通过Shamir秘密共享与其他用户秘密地共享其私人种子bi以及私钥ski。
在此示例中,使用2 out of 3的秘密共享中可以用于容忍1个好奇用户。
Masking and uploading of local models.
为了提供每个单独模型的隐私,用户i∈{1,2,3}掩盖其模型xi如下:
$$
\begin{array}{l}
\tilde{\mathbf{x}}{1}=\mathbf{x}{1}+\mathbf{n}{1}+\mathbf{z}{1,2}+\mathbf{z}{1,3} \
\tilde{\mathbf{x}}{2}=\mathbf{x}{2}+\mathbf{n}{2}+\mathbf{z}{2,3}-\mathbf{z}{1,2} \
\tilde{\mathbf{x}}{3}=\mathbf{x}{3}+\mathbf{n}{3}-\mathbf{z}{1,3}-\mathbf{z}_{2,3}
\end{array}
$$
其中ni = PRG(bi),且zi,j= PRG(ai, j)是伪随机发生器生成的随机掩模。
然后用户i∈{1,2,3}将其masked的本地模型$$\tilde{\mathbf{x}}_{i}$$发送到服务器。
Aggregate-model recovery.
假设用户1在上一阶段drop。服务器的目的是计算模型X2 + X3的汇总。注意:
$$
\mathbf{x}{2}+\mathbf{x}{3}=\tilde{\mathbf{x}}{2} + \tilde{\mathbf{x}}{3}+(\mathbf{z}{1,2}+\mathbf{z}{1,3} - \mathbf{n}{2}-\mathbf{n}{3})
$$
因此,服务器需要重建Masks N2,N3,Z1,2,Z1,3以恢复X2 + X3。
为此,服务器必须为B2,B3,SK1中的每个值各收集两份shares,然后按(2)计算聚合模型。
我们注意到,Secagg要求服务器在每个重建的种子上计算PRG功能,以恢复aggregated masks,这构成了O(N^2^)的开销,并在运行时间里占了一大部分。
SECAGG+
secagg+通过用稀疏的程度O(log N)的稀疏随机图替换secagg的完整通信图来减少通信和计算负载,从而将mask reconstruction的开销从O(N)减少到O(N log N)
Secagg和Secagg+中,重构pairwise随机掩码在扩展到大量用户时会带来主要的瓶颈。
重要的是要注意,Secagg和Secagg+不能应用于异步FL,因为不能保证基于密钥协商协议的pairwise随机掩码的抵消。
4. LIGHTSECAGG PROTOCOL
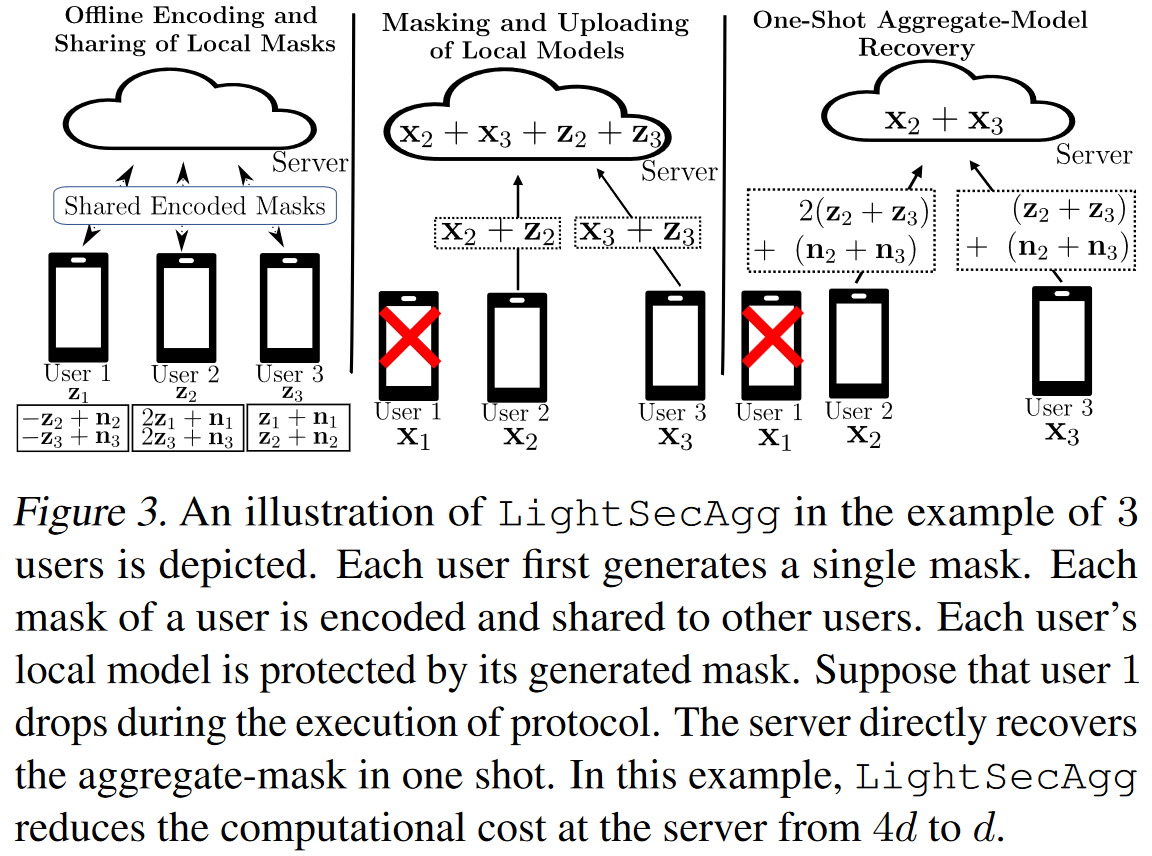
在提供LightseCagg的一般描述之前,我们首先通过之前同步设置中的3-user示例来说明其关键想法。如图3所示,LightseCagg具有以下三个阶段。
Offline encoding and sharing of local masks

用户i∈{1,2,3}从$$F^d_q$$随机选择zi和ni。用户i∈{1,2,3}将zi的masked version创建为:
$$
\begin{array}{l}
\tilde{\mathbf{z}}{1,1}=-\mathbf{z}{1}+\mathbf{n}{1}, \tilde{\mathbf{z}}{1,2}=2 \mathbf{z}{1}+\mathbf{n}{1}, \tilde{\mathbf{z}}{1,3}=\mathbf{z}{1}+\mathbf{n}{1} \
\tilde{\mathbf{z}}{2,1}=-\mathbf{z}{2}+\mathbf{n}{2}, \tilde{\mathbf{z}}{2,2}=2 \mathbf{z}{2}+\mathbf{n}{2}, \tilde{\mathbf{z}}{2,3}=\mathbf{z}{2}+\mathbf{n}{2} \
\tilde{\mathbf{z}}{3,1}=-\mathbf{z}{3}+\mathbf{n}{3}, \tilde{\mathbf{z}}{3,2}=2 \mathbf{z}{3}+\mathbf{n}{3}, \tilde{\mathbf{z}}{3,3}=\mathbf{z}{3}+\mathbf{n}{3}
\end{array}
$$
用户i∈{1,2,3}对每个用户j∈{1,2,3}发送$$\tilde{\mathbf{z}}{i,j}$$。
因此,用户i∈{1、2、3}接收 $$\tilde{\mathbf{z}}_{j,i}$$ for j∈{1、2、3}。
在这种情况下,此过程提供了robustness against 1 dropped user以及 privacy against 1 curious user。
Masking and uploading of local models.
为了使每个单独的模型私有,每个用户i∈{1,2,3}掩盖其本地模型,如下所示:
$$
\tilde{\mathbf{x}}{1}={\mathbf{x}}{1}+{\mathbf{z}}{1},
\tilde{\mathbf{x}}{2}={\mathbf{x}}{2}+{\mathbf{z}}{2},
\tilde{\mathbf{x}}{3}={\mathbf{x}}{3}+{\mathbf{z}}_{3},
$$
并将masked model发给server
One-shot aggregate-model recovery.
假设用户1在上一阶段drop。为了恢复模型X2 + X3的模型聚合,服务器只需要知道聚合的掩码Z2 + Z3即可。
要恢复Z2 + Z3,幸存的用户2和用户3分别发送$$\tilde{\mathbf{z}}{2,2}+\tilde{\mathbf{z}}{3,2}$$和$$\tilde{\mathbf{z}}{2,3}+\tilde{\mathbf{z}}{3,3}$$给server:
$$
\tilde{\mathbf{z}}{2,2}+\tilde{\mathbf{z}}{3,2}=2({\mathbf{z}}{2}+{\mathbf{z}}{3})+\mathbf{n}{2}+\mathbf{n}{3}\
\tilde{\mathbf{z}}{2,3}+\tilde{\mathbf{z}}{3,3}=({\mathbf{z}}{2}+{\mathbf{z}}{3})+\mathbf{n}{2}+\mathbf{n}{3}
$$
从用户2和用户3接收到消息后,服务器可以通过one-shot计算直接恢复聚合的掩码,如下所示:
$$
{\mathbf{z}}{2}+{\mathbf{z}}{3}=\tilde{\mathbf{z}}{2,2}+\tilde{\mathbf{z}}{3,2}-(\tilde{\mathbf{z}}{2,3}+\tilde{\mathbf{z}}{3,3})
$$
然后,服务器通过从 $$\tilde{\mathbf{x}}{2}+\tilde{\mathbf{x}}{3}$$中减去Z2 + Z3来恢复聚合模型X2 + X3。
与必须重建dropped用户的随机种子的Secagg不同,LightseCagg使服务器能够通过one-shot恢复来重建aggregate of masks。
与Secagg相比,在这个简单的示例中,LightseCagg将服务器的计算成本从4d降低到d。
4.1 General Description of LightSecAgg for Synchronous FL
Remark 2:
请注意,不必在LightseCagg中的每对用户之间建立稳定的通信链接。即使由于不稳定的通信链接,多至N-U用户掉落或延迟,服务器仍然可以重建聚合掩码。
Remark 3:
我们注意到,LightseCagg直接适用于对本地模型做加权聚合的安全聚合。
4.2 Extension to Asynchronous FL
5. THEORETICAL ANALYSIS
5.1 Theoretical Guarantees
Remark 4:
定理1提供了隐私和辍学保证之间的权衡,即,LightseCagg可以通过减少Dropout-resility保证和vice versa来增加隐私保证,反之亦然。
Remark 5:
从训练收敛的角度来看,LightseCagg仅在用户的本地模型更新中添加了量化步骤。
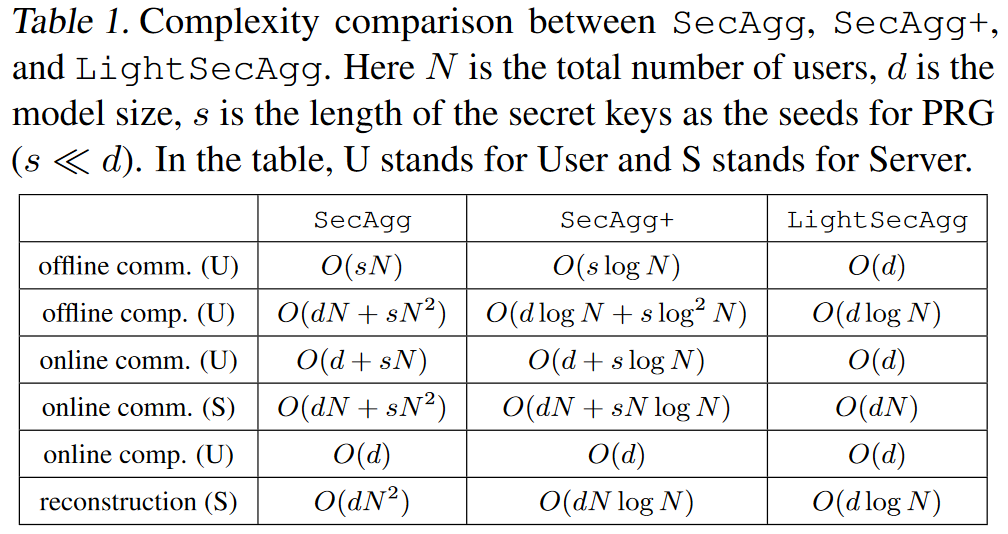
5.2 Complexity Analysis of LightSecAgg
6. SYSTEM DESIGN AND OPTIMIZATION
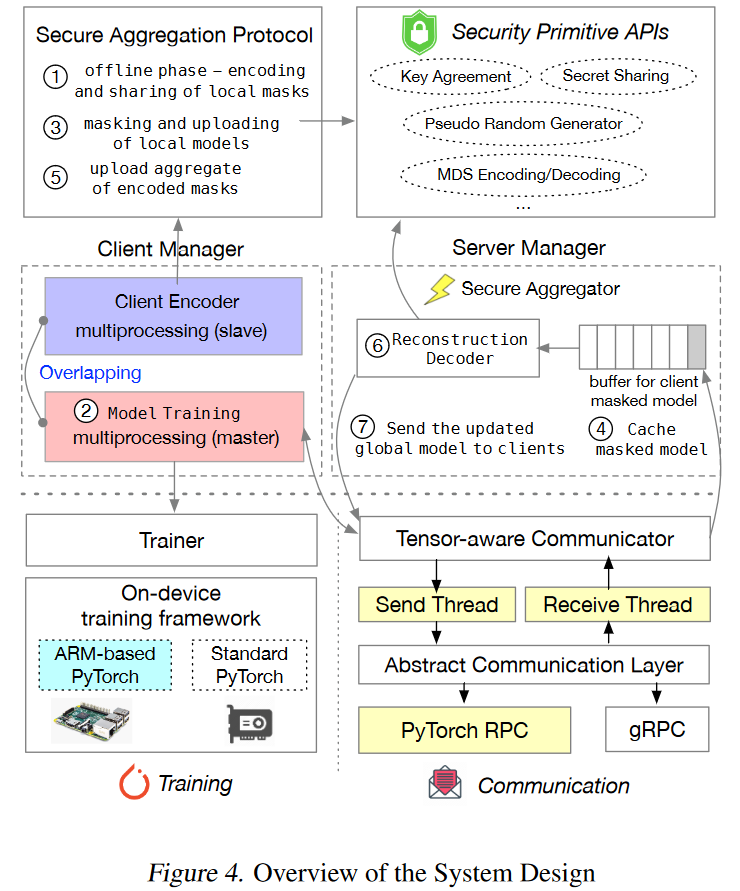
Parallelization of offline phase and model training.
Optimized federated training system and communication APIs via tensor-aware RPC (Remote Procedure Call).
7. EXPERIMENTAL RESULTS
7.1 Setup
Dataset and models.
Dropout rate.
为了建模dropped的用户,我们随机选择pN个用户,其中p是dropout rate。我们考虑最糟糕的情况(Bonawitz等,2017),其中所选的PN用户在上传masked model后drop。所有三个方案均提供隐私保证T = n/2和三种不同dropout rate的resiliency:p = 0.1,p = 0.3和p = 0.5。
正如我们可以看到的那样,当仔细选择在训练期间可能在线稳定的设备时,辍学率高达10%;当考虑间歇性连接的设备时,在每日活跃设备为10M时,只有多达10K设备可以同时参与训练(1:1000)。
Number of users and Communication Bandwidth.
在我们的实验中,我们最多训练n = 200个用户。测得的实际带宽为320MB/s。我们还考虑了4G(LTE-A)和5G蜂窝网络的其他两个带宽设置,正如我们稍后讨论的那样。
Baselines.
我们将LightseCagg的性能与两个基线方案进行了分析和比较:SecAgg和SecAgg+(其实还有其他的SA协议:TurboAgg,FastSecAgg)。我们将secagg和secagg+用于我们的基线,因为其他方案的安全性相对弱一点。
7.2 Overall Evaluation and Performance Analysis
对于performance analysis,我测量a single round of global iteration的总运行时间,其中包括模型训练和安全聚合,同时逐渐增加用户数量N,以供不同用户dropouts。
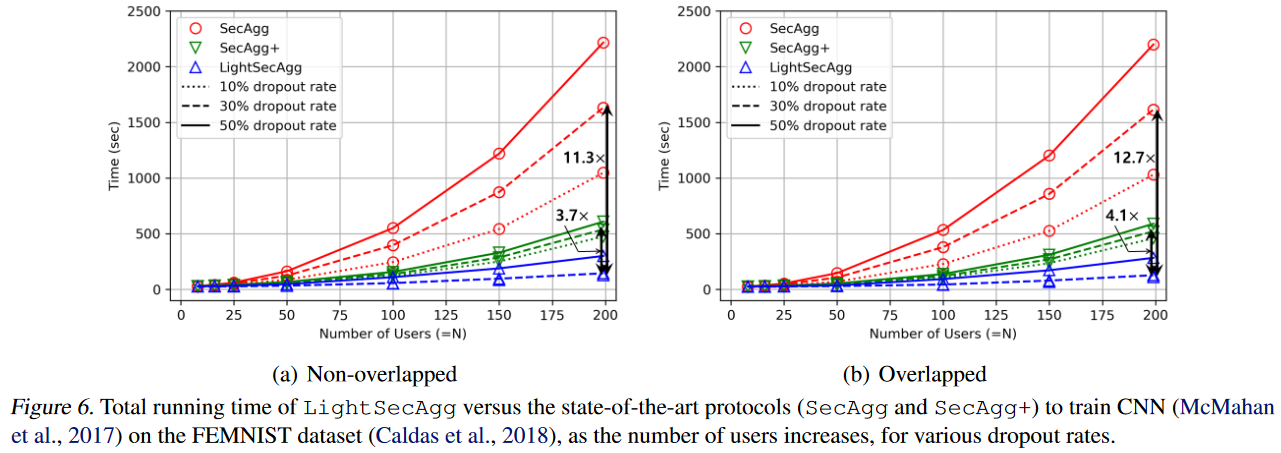
我们在FEMNIST数据集(McMahan等,2017)上训练CNN的结果(Caldas等,2018)如图6所示。
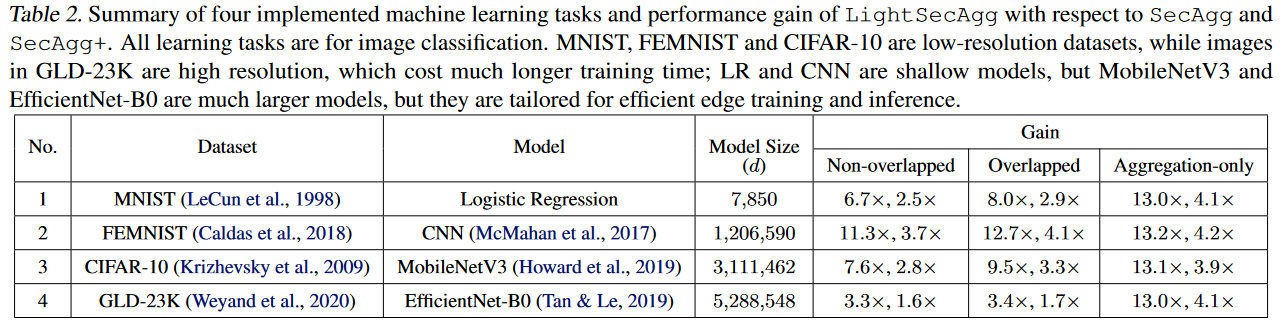
在表2中提供了the performance gain of LightSecAgg with respect to SecAgg and SecAgg+ to train the other models
Impact of dropout rate
Secagg和Secagg+的总运行时间随dropout rate而单调增加。这是因为他们的总运行时间由服务器上的mask recovery主导,这与用户数量是平方关系。
Non-overlapping v.s. Overlapping
在offline phase,LightseCagg相比于基线协议需要更多的通信和更高的计算成本,并且overlapped的实施有助于减轻此额外的成本。
Impact of Bandwidth
7.3 Performance Breakdown
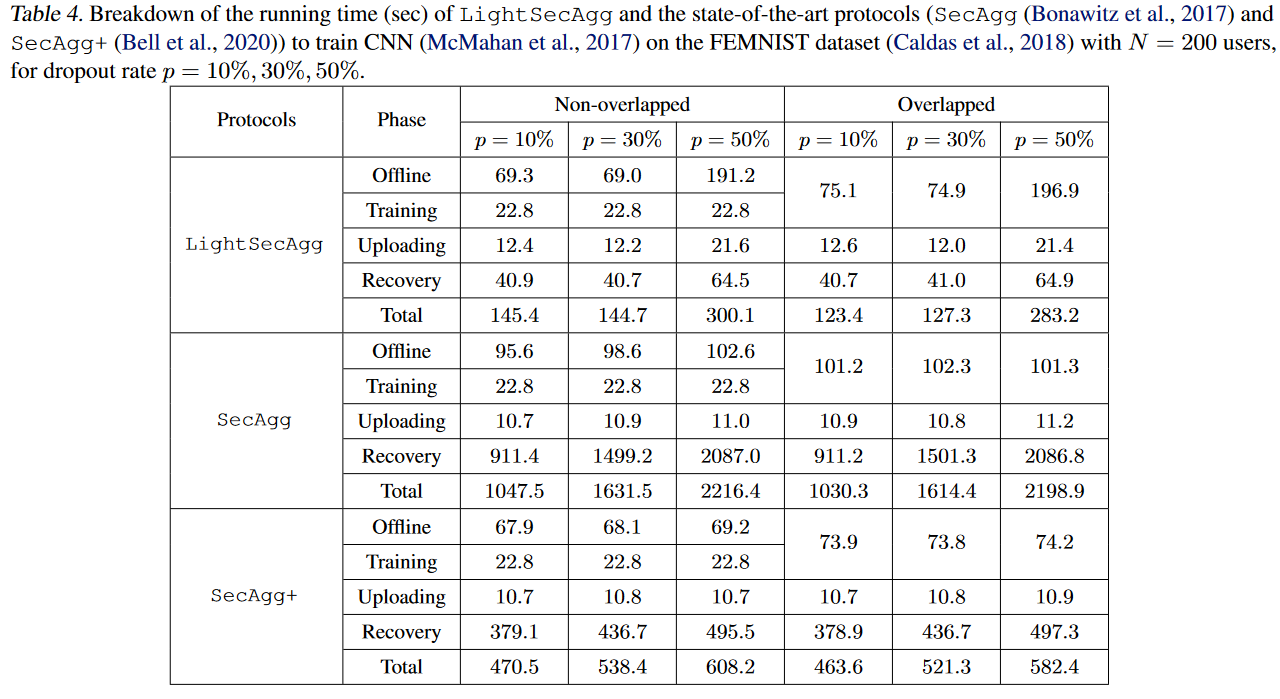
为了进一步研究LightseCagg的primary gain,我们在表4中提供了训练CNN的总运行时间(McMahan等,2017)(Caldas等,2018)。确认primary gain在于LightseCagg带来了服务器端复杂性降低,尤其是对于大量用户而言。
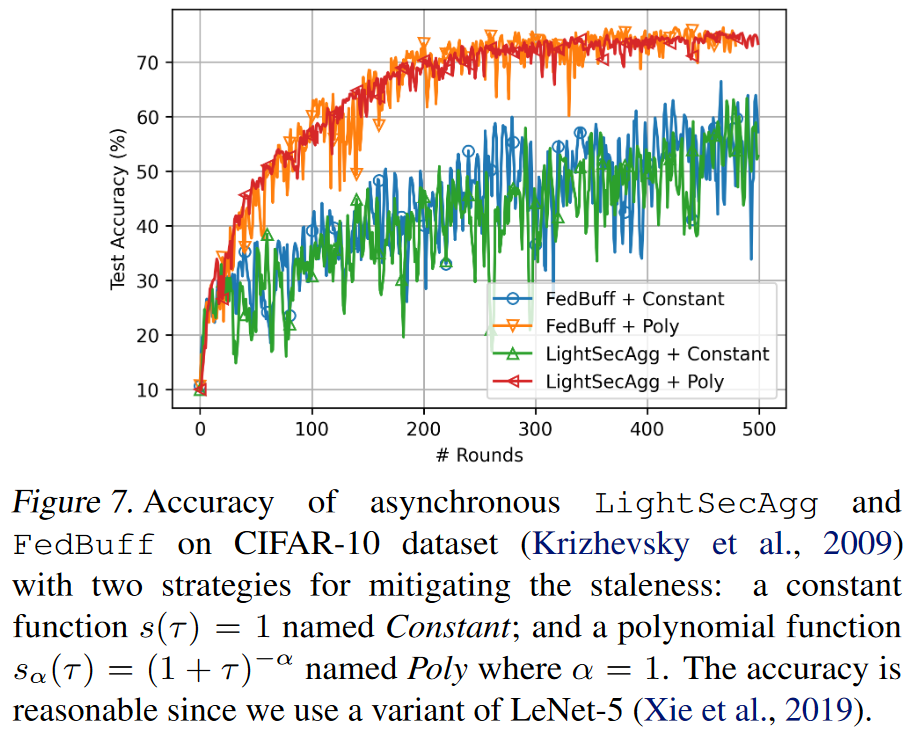
7.4 Convergence Performance in Asynchronous FL
在这里的实验中,我们关注的是LightseCagg的收敛性能与FedBuff(Nguyen等,2021)相比,研究异步和量化对性能的影响。在图7中,我们证明了LightseCagg在CIFAR-10数据集上与FedBuff的性能几乎相同,而且LightSecAgg还包括了量化噪声,以保护用户本地本地更新的隐私。
8. CONCLUSION AND FUTURE WORKS
本文提出了LightseCagg,这是一种在同步和异步FL中安全聚合的新方法。与最先进的协议相比,LightseCagg通过利用幸存用户的one-shot aggregate-mask来减少FL中模型聚合的开销,同时提供相同的隐私和dropout保证。
在现实的FL框架中,通过广泛的经验结果,还表明LightseCagg可以为培训各种机器学习模型提供大幅加速基线协议。尽管我们专注于这项工作(根据诚实但奇怪的威胁模型)的隐私,但有趣的未来研究是将LightseCagg与最先进的Byzantine robust的聚合协议相结合,可以mitigate Byzantine users while ensuring privacy。

