
Towards Class-balanced Privacy Preserving Heterogeneous Model Aggregation
摘要
异构模型聚合(HMA)是一个有效的范式,可以将在架构和目标任务上有所不同的异构模型聚合为一个comprehensive model。
最近的作品采用知识蒸馏将异构设备的所学到的特征与预测进行的知识合并以实现HMA。但是,他们中的大多数人都忽略了所学到的特征的披露会使设备模型暴露于隐私攻击中。
此外,聚合模型可能会遭受因对每个类别的合并知识的分布不平衡导致的不平衡的监督(imbalanced supervision),并且show class bias。
在本文中,为了解决这些问题,我们提出了一种基于响应的(response-based)类平衡(class-balanced)的异构模型聚合机制,称为CBHMA。它可以以隐私的方式有效地实现HMA,并减轻聚合模型中的class bias。
具体而言,CBHMA通过仅使用其响应信息来聚合设备模型,以降低其隐私泄漏风险。为了减轻监督不平衡的影响,CBHMA定量测量每个类别的imbalanced supervision level。基于此,CBHMA自定义了每个类别的fine-grained错误分类成本,并利用此类成本来调整基于响应的HMA算法中每个类的重要性(对于有着weaker supervision的类别给它more importance)。
在两个现实世界数据集上进行了广泛的实验证明了CBHMA的有效性。
1. Intro
异构模型聚合(HMA)是一个有效的范式,可以将在架构和目标任务上有所不同的异构模型聚合为一个comprehensive model。
HMA研究现状
现有的一些HMA方案(例如:基于知识蒸馏(KD)4-9):
核心思想:是将On Device模型和汇总模型分别为教师和学生,并迫使学生模仿教师的learned features和预测,以使知识合并。
缺点:learned features的披露使设备模型易受隐私攻击,例如模型推理攻击[10],[11]。
解决方案:
- 仅使用异构分类器的输出信息来整合知识([12] - [14])
- 使用了一些典型的隐私保护技术,例如安全聚合技术来保护隐私[15]。
总结:在这些基于KD的HMA方法中,每个设备模型都将其学习的知识转移到了汇总模型,这称为“dark knowledge”。它包含有关类别相互关系、模型如何泛化等等信息[16],[17]。
来自异构的现实设备模型的合并知识为训练聚合模型提供了监督,并帮助聚合模型模仿了设备模型的行为,以更快地实现有竞争力的性能。但是,被忽略的是,关于每个类别的合并知识可能是不平衡的,这导致汇总模型在不平衡的监督下受过训练。不平衡的监督问题是两个方面:
- 首先,由于设备模型的目标类别的分布不平衡,对每个类别的综合知识数量可能不平衡。
- 其次,由于设备模型在每个类别上的性能所有偏差,有关每个类的综合知识的质量可能会有所不同。
正如许多作品[18] - [20]中所研究的那样,不平衡的监督可能导致类别偏见(即:归属于某个有weaker supervision的类别的实例,相对于那些属于stronger supervision类别的实例来说,会更频繁地被错误分类),这会影响分类器的整体性能。现有作品主要关注训练数据中类不平等分布导致的不平衡监督问题,并从两个方面提出解决方案,即:数据级[21] - [25]和算法级别[26] - [29 ]。
- 数据级方法:通过重新采样来调整不同类别的分布。
- 算法级方法:使用cost-sensitive的学习方法,通过proper misclassification成本,来修改学习算法以减轻其对多数群体的偏见。
然而,仍然需要研究HMA中由每个类别的合并知识的不均匀分布(Uneven-knowledge for short)导致的不平衡监督,这激发了我们更深入地研究类偏见(class bias)的问题,并设计了一种新颖的HMA方法,该方法是一种新颖的HMA方法,可以实现异构模型的类平衡集成(class-balanced integration)。
response-based class-balanced heterogeneous model aggregation mechanism
在本文中,我们专注于HMA中不均匀的知识和隐私泄漏问题引起的不平衡监督问题,并旨在生成一个class-balanced的集成模型,并尽可能少地使用来自设备模型的信息。为了实现我们的目标,我们面临两个挑战:
第一个是如何在实现有效HMA的同时降低设备模型的隐私泄漏风险?
第二个是如何衡量和减轻不平衡的监督对聚合模型训练的影响?
不平衡的知识会导致对汇总模型的监督不平衡,但不能像衡量训练数据中类的不平等分布的程度那样来衡量。
具体而言,当衡量训练数据中类不等分布时,我们通常可以直接计数和比较属于每个类别的数据样本的数量,其中属于每个类别的数据样本的比例通常会变化,表明类别中的类不平衡训练数据。但是,当衡量不平衡知识时,由于缺乏对上述“dark knowledge”的明确和合理的定义,因此无法准确量化有关每个类别的合并知识。因此,弄清楚监督对聚合模型的训练的影响,以及如何减轻这种影响以改善模型性能的影响是有挑战性的。
为了解决挑战,我们提出了CBHMA,这是一种基于响应的类平衡的异构模型聚集机制。它可以减轻汇总模型中的class bias,并提高其性能,同时保证对异构的设备模型的隐私保护。出于隐私原因,CBHMA通过仅使用其响应信息来聚合设备模型,这样可以防止设备模型的learned features的隐私泄露,在这种情况下,聚合模型聚合的是异构设备模型的response-based知识,而不是feature-based知识。
为了减轻聚合模型中的class bias,CBHMA利用了cost-sensitive的学习方法来根据不平衡监督状况在训练过程中调整每个类的重要性。
首先,它衡量了在数量和质量方面为每个设备模型提供的每个类别的不平衡监督级别。
其次,它根据设备模型的输出估算了类间的相关性,然后根据衡量的不平衡监督水平和估计的类间相关性来定制每个类的fine-grained misclassification成本。
定制misclassification成本应遵循以下两个原则:
- 较弱监督的类别应具有更高的misclassification成本。
- 将某个类别的图像错误分为较不相关的类别要比将其划分为高度相关的类别应该更为costly。
最后,定制的错误分类成本被用作修改基于响应的HMA算法以构建类平衡loss function的加权因子。有了这项措施,可以减轻监督不平衡的影响,并且可以改善聚合模型的性能。
Contrib
- 我们提出了一种基于响应的类平衡的异构模型聚合机制,称为CBHMA,以整合异构的设备模型,并以隐私保护方式来减轻聚合模型中的类偏见。据我们所知,这是研究和解决因异构模型聚合中每个类别的合并知识分布不平衡的分布而引起的不平衡监督问题的第一项工作。
- 我们建议定量分析每个类别的不平衡监督级别,并估计类间相关性。基于此,我们自定义了细化的错误分类成本,以在聚合模型的训练中re-weight每个类别的分布,从而实现类平衡的异构模型聚合。
- 我们对现实世界数据集进行了广泛的实验,实验结果表明,CBHMA优于基准,同时提供更强的隐私保证。
2. SYSTEM MODEL AND PROBLEM DEFINITION
2.1 System Model
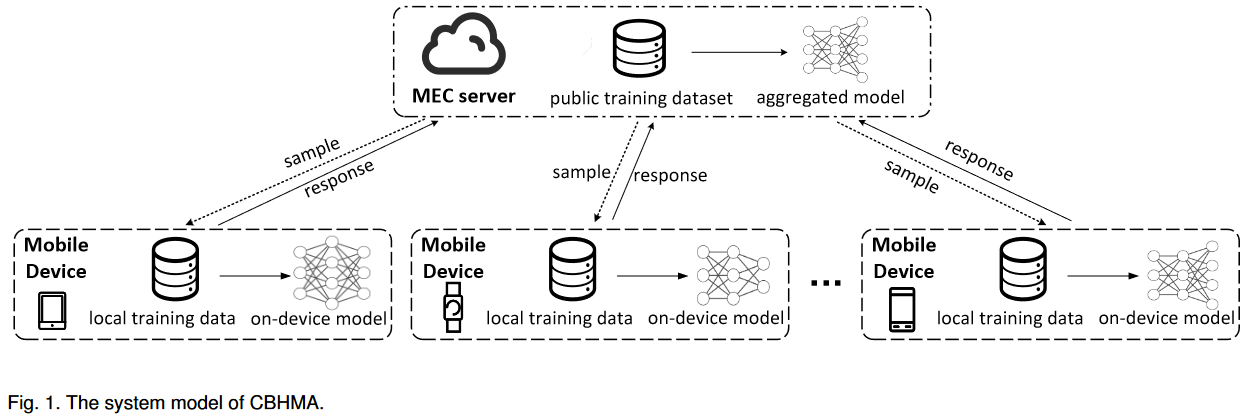
在本文中,我们考虑了由MEC服务器和大量移动设备组成的移动边缘计算(MEC)系统中的异构模型聚合(HMA),这如图1所示。
每个智能设备都有自己的在本地数据上训练的分类模型,我们称其为设备模型。实际上,每个智能设备可能会收集不同类型类别的图像,其本地模型可能具有不同的体系结构。因此,设备模型在体系结构和目标任务上都可能有所不同。在我们对CBHMA的设计中,MEC服务器旨在通过仅使用其对公共训练样本的响应来汇总异构设备模型,并生成一个全面的汇总模型,以集成所有设备模型的分类能力。
2.2 Problem Definition
在下文中,我们首先定义本文要解决的基于响应的HMA问题,然后描述HMA过程中的不平衡监督问题,并总结本文的设计目标。
Response-based HMA
假设有M个智能设备,每个设备i用本地数据训练自己的设备模型Ti,每个设备模型Ti可以根据一张输入图片x预测其标签$y \in L_i$,其中Li是Ti的目标类别集合。
设备模型可能有不同的架构,可能为不同的目标而训练。
例如:对于$i,j \in {1, 2, …, M}$以及i≠j的情况下,会存在Li≠Lj,甚至|Li|≠|Lj|
不同的设备模型之间还可能有重叠的目标类别。
例如:$\exist i,j \in {1, 2, …, M}$以及i≠j的情况下,Li∩Lj≠∅
我们用Ls来表示所有设备模型目标类别的并集,用$D_s={(x_a,y_a)}^N_{a=1}$来表示一个小规模的公共数据,其中包含来自L个类别的N张图片${x_a}^N_{a=1}$,以及它们对应的标签${y_a}^N_{a=1}$。并且每个类别的图片数量是相等的。
关于隐私保护问题,我们假设设备模型的目标类别集合是唯一可以被获取的信息(即:output logits)
那么Response-based HMA的目标就是:在可获取信息受限的情况下,使用Ds来整个设备模型,并生成一个目标类别集合为Ls的comprehensive model S。
在本文中,我们倾向于根据知识蒸馏(KD)解决上述问题,并分别将异构的设备模型和聚合模型分别作为教师和学生。 KD使学生能够在老师的监督下通过小型训练来快速学习新的复杂概念。 Hinton等 [16]首先概括KD并提议提炼教师网络的知识,也就是logits(例如,网络中最后一层的输出),因为logits带有教师学到的dark知识模型。
假设有一个教师模型Nt和学生模型Ns,并且它们对于同一张输入图片x有输出logits $o^t$和$o^s$。x对应的ground-truth向量是y。那么KD的训练目标可以表示为:
$$
\mathcal{L}=(1-\alpha) * \phi\left(y, \eta\left(o^{s}, 1\right)\right)+\alpha * \phi\left(\eta\left(o^{t}, \tau\right), \eta\left(o^{s}, \tau\right)\right)
$$
其中η是softmax函数,τ> 1是软化操作的温度参数,$\phi$是损耗函数(例如,cross-entropy loss)。第一项是预测损失,第二项是蒸馏损失,α是这两个项的平衡系数。前者matches学生模型的预测和ground-truth向量,后者matches教师模型与学生模型之间的logits。
请注意,KD不仅可以将基于响应的知识从教师转移到学生,还可以转移基于特征的知识(例如,直接层(immediate layer)的输出)[30] - [32]和基于关系的知识(例如,不同层之间的关系)[33],[34]。此外,在典型的KD框架中,教师可以是模型或模型的ensemble[35],[36]。
Imbalanced Supervision Issue.
不平衡的监督问题是两个方面:
- 数量:首先,由于设备模型的目标类别的分布不平衡,对每个类别的综合知识数量可能不平衡。
- 质量:其次,由于设备模型在每个类别上的性能所有偏差,有关每个类的综合知识的质量可能会有所不同。
最终会导致每个类别的监督级别不平衡。
这一部分中,我们首先在平衡的监督和不平衡监督下模拟HMA,然后比较其性能以讨论不平衡监督的影响。
在我们的实验中,我们通过Fashion MNIST数据集的5个异构的设备模型实现了HMA。Fashion MNIST数据集中共有10类训练样本(即0至9),每个类别的训练样本数量是相同的。
我们设置的每个设备模型都可以分类3到6个类,而集成模型可以对所有10个类进行分类。为了在平衡监督和不平衡监督下模拟HMA案件并说明监督不平衡的影响,我们在三个设置下进行实验(即平衡的监督设置(简称BS),不平衡的监督设置1(简称IS-1) ,以及逆不平衡监督设置2(简称为IS-2)。为了方便起见,在所有这些情况下,我们根据每个类别的聚合知识数量是否不平衡来判断不均匀知识的存在。这些设置的详细信息可以描述如下。
- BS:对于每个类,都有3种可以对其进行分类的设备模型。因此,在模型聚合过程中,集成模型可以从每个类别的3个设备模型中融合知识。
- IS-1:综合模型可以分别从从1台设备上对1类的知识进行融合,可以从5台设备上对9类的知识进行融合,并可以从剩下的3个设备中对其他类别进行融合有关其他类的知识。
- IS-2:综合模型可以分别从从5台设备上对1类的知识进行融合,可以从1台设备上对9类的知识进行融合,并可以从剩下3个设备中对其他类别进行合并知识。
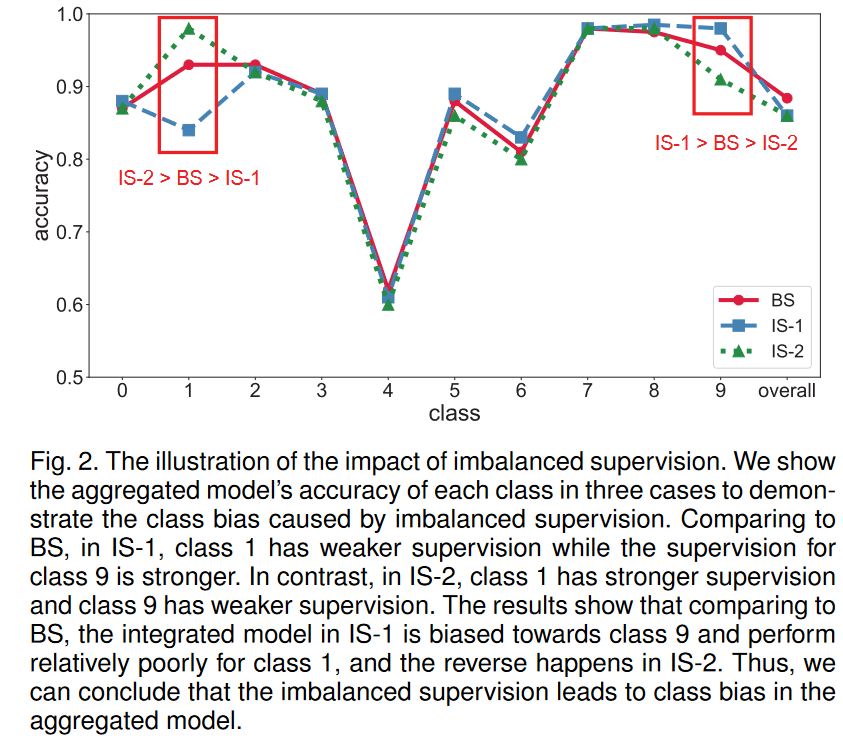
在BS中,由于集成模型可以从每个类别的3个设备模型中合并知识,因此可以将每个类的聚合知识分布视作uniform,因为有关每个类的聚合知识的数量可以看作是均匀的。在这种情况下,聚合模型在平衡的监督下进行训练。
同样,我们可以得出结论,在IS-1中,1类的监督较弱,而9类的监督性更强,而其他类别则具有与BS相同的监督。在IS-2中,与IS-1的区别在于1级和9类交换其监督级别。
图2中显示了这三个设置下每个类的集成模型的分类精度类别在很大程度上保持不变。 IS-2中的1级和9类的情况是相反的。也就是说,具有更强监督的类别的分类准确性要高于监督较弱的类别。此外,BS中集成模型的总体性能比IS-1和IS-2中的更好。因此,经验证明,由HMA中的不平衡知识造成的不平衡监督导致综合模型对stronger supervision的类别有bias,并且对weaker supervision的类别有discrimination,从而损害了聚合模型的表现。
设计目标:
综上所述,本文的设计目标是处理HMA中的监督和隐私泄漏问题,并生成一个平衡的汇总模型,同时为异构的设备模型提供隐私保证。
3. RESPONSE-BASED CLASS-BALANCED HMA
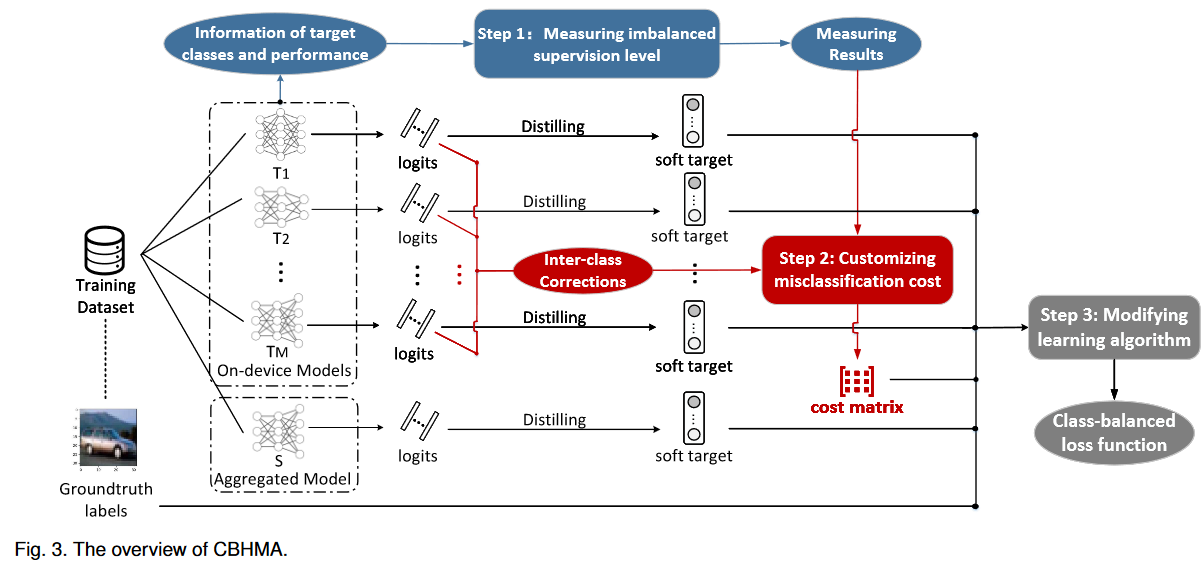
CBHMA的概述如图3所示。CBHMA中有三个步骤:
- 步骤1:根据异构设备模型提供的信息来测量每个类别的监督水平的不平衡程度,从两个方面衡量:数量和质量
- 步骤2:根据不平衡的监督水平和类间的相关性,为每个类别定制细粒度的错误分类成本。
- 步骤3:使用自定义的错误分类成本修改基于响应的HMA算法,以调整每个类在训练过程中的重要性,并构建一个类平衡的损失函数。
3.1 Measuring Imbalanced Supervision Level
不平衡的监督问题是由于关于每个类别的合并知识的不均匀分布(简称为不均匀的)导致的,因此我们需要估算合并知识以衡量不平衡的监督水平。但是,没有对于“dark knowledge”的一种明确和可量化的定义的话,无法准确衡量有关每个类的合并知识。
取而代之的是,我们建议近似指示有关每个类别的合并知识的相对数量和质量——通过异构的设备模型提供的信息,即每个类别的目标类别和分类精度,来做到这一点。该方法无法准确量化有关每个类别的合并知识,但在统一近似标准下对不同类别的合并知识进行了公平的可比性。更具体地,即使我们无法准确测量每个类别的合并知识的数量,当我们以相同方式指示所有类别的合并知识的数量时,我们可以有效地揭示每个类别的相对融合知识的相对数量。这也适用于每个班级合并知识的相对质量。然后,我们可以根据合并知识的相对数量和质量来测量不平衡的监督水平。
一个设备模型的目标类集包含l类表示,该模型可以预测某样本属于l类的概率。因此可以通过其对样本的响应传输与l相关的知识。
在我们基于响应的HMA设置中,每个设备模型都有其自己的目标类集,这些目标类集可能会重叠。如果在这些设备模型的目标类集合中类别l的概率很高,那么就可以提供很多l类别相关的知识,那么在聚合模型中关于类别l的聚合知识的数量就会很大。
因此,我们使用每个类的类频率来指示该类的合并知识的数量。我们使用$I_i∈R^L$指示设备模型Ti的目标类信息。$I_i$的l-th元素当且仅当$l \in L_i$时有$I_i^l=1$,仅当l∈Li,否则$I_i^l=0$。类l的频率可以通过$F_l = \sum^M_{i=1}I^l_i$计算。然后,类别l的聚合知识的相对数量可以用来$F_l/{\sum^L_{j=1}F_j}$衡量。
根据对每个类别的合并知识的相对数量和质量的近似估计,我们可以大致测量每个类别的监督水平的不平衡监督水平。直觉是,相对数量越大,合并知识的相对质量越好,监督水平就越高。让$G_l$表示l类的不平衡监督水平,然后可以通过以下方式测量:
$$
G_{l}=\frac{F_{l}}{\sum_{j=1}^{L} F_{j}} \cdot \frac{P_{l}}{\sum_{j=1}^{L} P_{j}}
$$
更大的$\frac{F_{l}}{\sum_{j=1}^{L} F_{j}}$和$\frac{P_{l}}{\sum_{j=1}^{L} P_{j}}$代表类别l有更大相对数量和质量,然后就会导致Gl值更大——也就是说类别l在训练聚合模型的过程中有更强的监督。
3.2 Customizing Misclassification Cost
在本文中,我们倾向于根据基于成本敏感的学习方法调整每个类在学习算法中的重要性,从而减轻HMA不平衡监督的影响。为此,需要对每个类别的proper misclassification成本进行修改,以修改学习算法,以减轻其对stronger监督的类别的bias。
在本节中,我们首先简要介绍了成本敏感的学习,然后考虑不平衡的监督水平和类间的相关性来为每个类别定制细粒度的错误分类成本。有两种错误分类成本定制的原则。
- 较弱监督的类别应具有更高的misclassification成本。反之以此类推
- 将某个类别的图像错误分为较不相关的类别要比将其划分为高度相关的类别应该更为costly。
A brief Introduction to cost-sensitive learning.
大多数分类器都认为所有类别的错误分类成本都是相同的。但是,在某些应用程序方案中,对不同类别具有不同级别的关注会更合理。例如,错误分类某些严重疾病的后果比错误分类不太严重的疾病更为关键。成本敏感的学习[37],[38]为不同的类别分配了不同的错误分类成本,并将其用作加权因子以re-weight损失。因此,它通常用于处理不平衡的分类。通常,将少数类别分为多数类别的成本比将多数类别分为少数类别要高。
Measuring inter-class correlations.
在每个类别的监督水平不平衡的情况下,我们可以确定每个类别的错误分类成本的粗糙水平(与我们要定制的细粒度成本相对)。但是,从提高模型准确性的角度来看,将一个类别分为其他类别的样本错误分类的成本应不同。因此,我们建议在成本分配中考虑类间相关性,以自定义每个类别的细粒度错误分类成本。
分类模型学到的dark知识包含有关类相似性和相关性的信息。因此,我们充分利用了设备模型的输出logits,这些模型带有一些学习到的dark知识以估计类间相关性。具体而言,输出logits中元素的相对大小可以反映相应类之间的相关程度。对于目标类集为{l1,l2,l3}的模型,而对于l1类的输入样本,模型的输出logits为(z1,z2,z3),如果z2/z1> z3/z1,我们可以推断l2类的图像是与l1类更相似。在我们的情况下,使用TI的输出logits,我们可以估计Li中的类之间的相关性。
令IDl表示目标类集合包含l的设备模型的ID集。也就是说,如果l∈Li,则i∈IDl。
使用的${T_i}{i \in ID_l }$这些模型的logits,我们可以估计$\bigcup{i \in ID_l}L_i$中l类别和其他类之间的相关性。
用zi表示Ti对于类别l的输入样本的输出logits,$r^i_l$代表类别l通过zi估计获得的类间相关性向量。其中第j个元素可以表示为$r^i_l(j)$,代表用zi来估计得出的类别l与类别j之间的相关性。
- 如果$j \in L_i$,我们可以通过zi(Y=j)和zi(Y=l)的相对大小来估计$r^i_l(j)$。Y是zi的索引
- 如果$j \notin L_i$,我们可以设置$r^i_l(j)=0$
这样我们就可以得到:
$$
r_{l}^{i}(j)=\left{\begin{array}{ll}
z_{i}(Y=j) / z_{i}(Y=l) & , j \in L_{i} \
0 & , j \in L_{s}-L_{i}
\end{array}\right.
$$
对于类别l,我们可以从${T_i}{i \in ID_l }$这些模型的logits来估计$|ID_l| $个类间相关性向量${r^i_l}{i \in ID_l }$。要得到最终类别l的类间相关性向量$r_l \in R^L$,可以将${r^i_l}_{i \in ID_l }$聚合起来。
用$I_i∈R^L$指示设备模型Ti的目标类信息,用$I_i^j$表示j是否属于Li。有了$I_i$,$r^i_l$中l个类别之间的相关性都可以被明确表示。
- 如果$j \in \bigcup_{i \in ID_l}L_i$,我们将$r_l$中第j个元素设置为${r^i_l(j)}_{i \in ID_l }$中非零的值的平均值
- 如果$j \notin \bigcup_{i \in ID_l}L_i$,我们将$r_l$中第j个元素设置为0
上述规则可以表示为:
$$
r_{l}(j)=\left{\begin{array}{ll}
\frac{1}{\sum_{i \in \mathrm{ID}{l}} I{i}^{j}} \sum_{i \in I \mathrm{D}{l}} r{l}^{i}(j) & , j \in \bigcup_{i \in I D_{l}} L_{i} \
0 & , j \in L_{s}-\bigcup_{i \in I D_{l}} L_{i}
\end{array}\right.
$$
最终的所有类别的类间相关性向量可以形成一个类间相关性map $R \in R^{L \times L}$,并且$R=(r_1, r_2, …, r_L)^T$。第i行第j列的元素$R_{lj}$表示类别i与类别j之间的相关性。会存在某些$R_{lj}=0$的情况(原文有解释)。
我们用$X \in R^{L \times L}$来表示R中的元素是否为0。也就是说,对应位置上$R_{lj}=0$的话$X_{lj}=0$,$R_{lj}≠0$的话$X_{lj}=1$
为了避免0值,我们建立一个新的类间相关性map 相关性map $\hat R \in R^{L \times L}$
$$
\hat{R}{l j}=\left{\begin{array}{ll}
\frac{1}{\sum{k=1}^{L} X_{l k}} \sum_{k=1}^{L} R_{l k} & , R_{l j}=0 \
R_{l j} & , R_{l j} \neq 0
\end{array}\right.
$$
最后,为了统一(unify)任意两个类之间的相关程度,我们设置了最终的类间相关性map $\overline R \in R^{L \times L}$,其中$\overline R_lj=\tfrac {\hat R_lj+\hat R_jl}{2}$。
Generating fine-grained misclassification cost matrix.
错误分类成本与Gl之间的关系:
$$
c_{l j} \propto\left(1 / G_{l}, \frac{\sum_{k=1}^{L} \bar{R}{l k}}{\bar{R}{l j}}\right)
$$
为了反映上面的关系,我们设计了如下单调递减函数:
$$
c_{l j}=g\left(G_{l}, \frac{R_{l j}}{\sum_{k=1}^{L} R_{l k}}\right)=-\log G_{l} \cdot \log \frac{\sum_{k=1}^{L} \bar{R}{l k}}{\bar{R}{l j}}
$$
等式(7)的构造能够满足之前提过的错误分类成本的原则。
根据等式(7)计算出所有类别的fine-grained misclassification cost之后, 我们可以生成成本矩阵CLXL。
3.3 Modifying Learning Algorithm
为了减轻聚合模型对类别的偏见,在训练聚合模型期间,应对较弱的监督的类别赋予更大的importance。为此,基于成本敏感的学习方法,我们将定制的错误分类成本作为加权因子,以修改基于响应的HMA算法,并迫使聚合模型更加关注较弱的监督的类别。在下文中,我们介绍了基于响应的HMA算法的典型过程。在此基础上,我们提出了用于异构模型聚合的类平衡学习算法。
The typical procedure of response-based HMA algorithm.
在基于响应的HMA中,采用KD来通过其响应信息(即logits)来帮助汇总模型从异构的设备模型上合并知识。基于响应的HMA算法的典型过程可以分为两部分。
- 首先,它采用了一种将异构模型和集成模型的输出关联的方法。
- 其次,它促使集成模型模仿异构分类器的输出和样本的ground-truth向量,以合并知识
假设对于$D_S$中的训练样本$(x_a, y_a)$,设备模型$T_i$具有输出logits ,而聚合的模型S具有输出logits $z^a∈R^L$,则$T_i$和S的预测概率向量(Soft target)可以通过SoftMax函数η计算:
$$
p_{i}^{a}=\eta\left(z_{i}^{a}, \tau\right), q^{a}=\eta\left(z^{a}, 1\right), \mathfrak{q}^{a}=\eta\left(z^{a}, \tau\right)
$$
……
基于响应的HMA的loss func可以表述为:
$$
\begin{aligned}
\mathcal{L} &=(1-\alpha) * \mathcal{L}{\text {pre }}+\alpha * \mathcal{L}{k d} \
&=-\frac{1}{N} \sum_{a=1}^{N}\left[(1-\alpha) *\left(y^{a} \log q^{a}\right)+\alpha *\left(\sum_{i=1}^{M} p_{i}^{a} \log \mathfrak{q}_{i}^{a}\right)\right]
\end{aligned}
$$
Class-balanced learning algorithm.
在典型的基于响应的HMA程序中,忽略了不平衡的监督问题。为了解决问题,我们使用定制的错误分类成本矩阵来修改基于响应的学习算法,以调整每个类别在训练过程中的重要性,并减轻聚合模型中的类别偏见。
我们首先使用定制的成本矩阵扰动聚合模型的软目标,然后使用修改后的输出构建类平衡的损耗函数。
CBHMA的类平衡loss func:
$$
\begin{array}{c}
\mathcal{L}{c b}=-\frac{1}{N} \sum{a=1}^{N}\left[(1-\alpha) * \log \frac{c_{l l} \exp \left(z^{a}(Y=l)\right)}{\sum_{k=1}^{L} c_{l k} \exp \left(z^{a}(Y=k)\right)}+\right. \
\left.\alpha * \sum_{i=1}^{M} \sum_{j \in L_{i}} p_{i}^{a}(Y=j) \log \frac{c_{l j} \exp \left(z^{a}(Y=j) / \tau\right)}{\sum_{k \in L_{i}} c_{l k} \exp \left(z^{a}(Y=k) / \tau\right)}\right]
\end{array}
$$
在这样的类平衡的损失函数中,每个类别从班级对损失计算的贡献将根据错误分类成本矩阵重新加权。
- 一方面,将对属于较高分类成本的类的样本给予更多的importance。
- 另一方面,样本的预测越不准确(即,不正确或不相关类别的概率很大),它对于学习算法的贡献就越大
这种类平衡的HMA可以减轻class bias,并提升模型acc。
我们想指出的是,尽管上述平衡学习算法是基于UHC方法设计的,但我们提出的机制也可以扩展到其他HMA算法,以减轻聚合模型中的类偏见。我们在以后的实验中对此进行了验证。
4. PERFORMANCE EVALUATION
4.1 Experiment Settings
Compared methods
据我们所知,我们的工作是解决HMA不平衡的知识造成的不平衡监督问题的第一项工作。为了评估我们提出的CBHMA的有效性,我们将其与四个基线和一个变体进行了比较。
四个基线描述如下:SKD1、SKD2、UHC、CFL
(见原文)
一个变体描述如下:CBHMA-E
(见原文)
Implement Details
有C1和C2两种配置
所有方法均由Python实施。
- C1:20 epochs,默认聚合模型架构为ResNet20
- C2:50 epochs,默认聚合模型架构为ResNet56
4.2 Results and Analysis
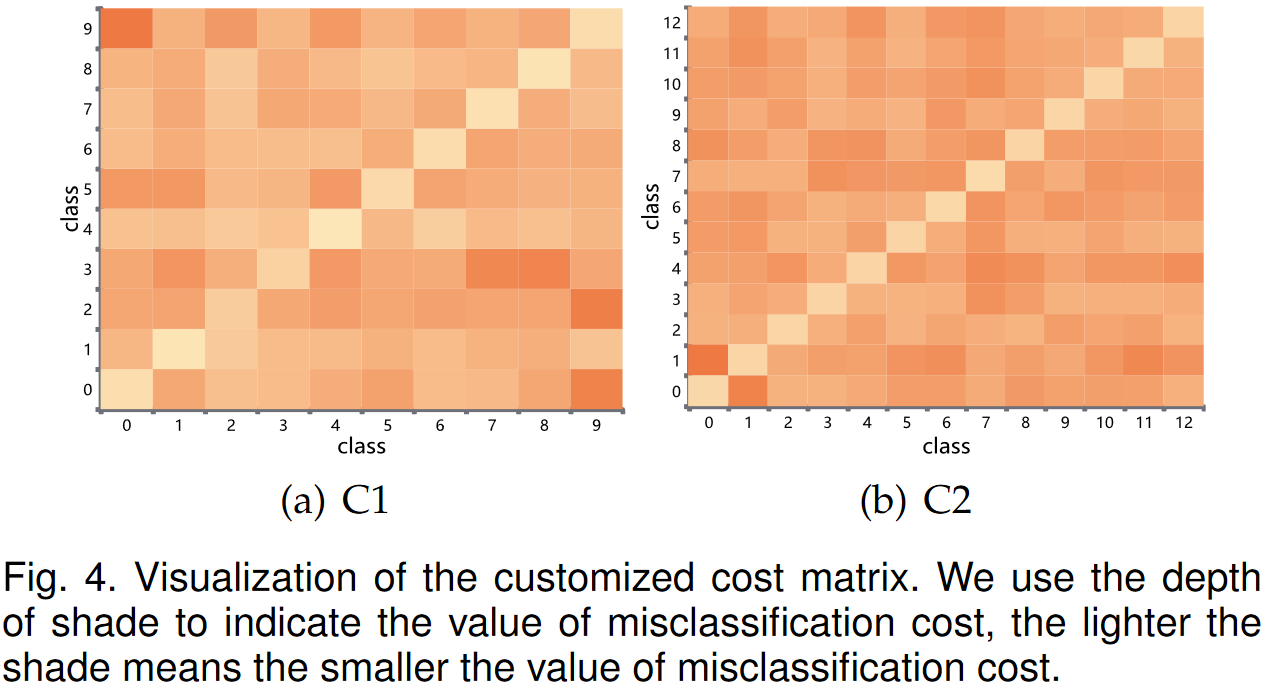
Visualization of the customized cost matrix.
在图4中,我们显示了在配置C1和C2下的定制成本矩阵的可视化。正如我们可以观察到的那样,每一行的每个列都有不同的值,在每一行中,对角线上的值是最小的。也就是说,每个班级的错误分类成本是不同的,当预测正确时,错误分类成本是最小的,这是理性的并且符合期望。
Comparing accuracy of each class.
为了证明我们所提出的机制确实可以减轻由HMA不平衡的知识引起的不平衡监督的影响,并减轻了总体模型中的类偏见,我们测试了UHC和CBHMA汇总模型中每个类别的准确性,结果是如图5所示。
我们可以发现,在配置C1下,UHC的汇总模型在第2、4、6类中的性能相对较差。它反映出在模型聚合过程中,第2、4、6类可能在监督下可能比其他类别较弱。还可以发现,与UHC相比,CBHMA在2、4、6上的准确性更好,减轻了在汇总模式下的类偏见。
同样,在配置C2下,我们可以观察到CBHMA可以提高大多数不偏向于UHC的类的准确性。因此,我们可以得出结论,我们提议的CBHMA可以处理不平衡的监督问题,并减轻汇总模型对weaker supervision类别的歧视。
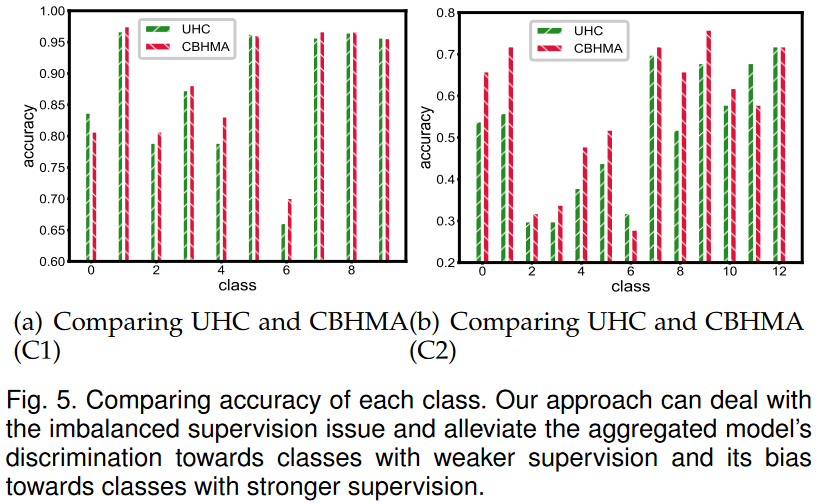
因此,我们可以得出结论,我们提议的CBHMA可以处理不平衡的监督问题,并减轻汇总模型对weaker supervision类别的歧视。
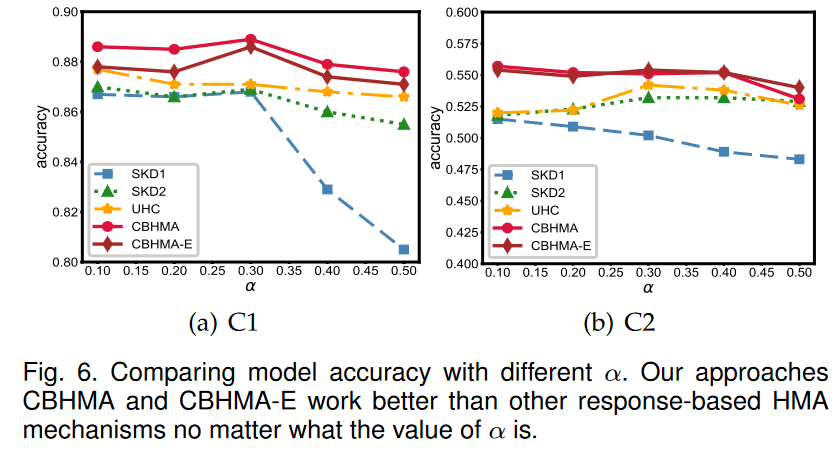
Performance vs. α.
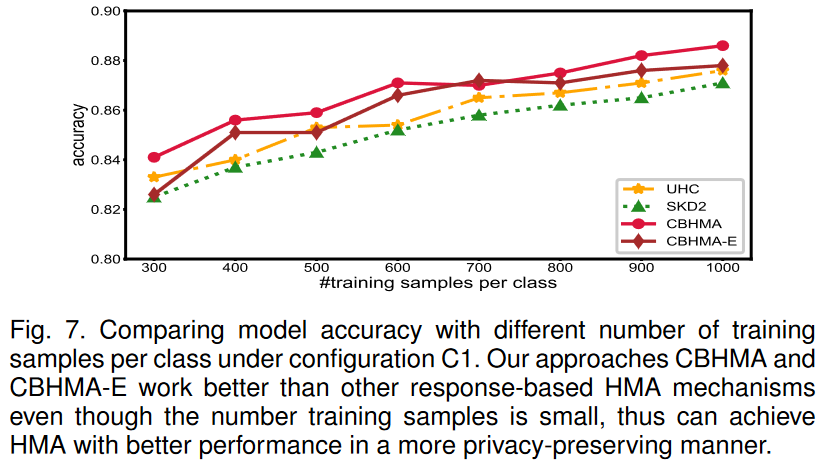
Performance vs. the number of training samples per class.
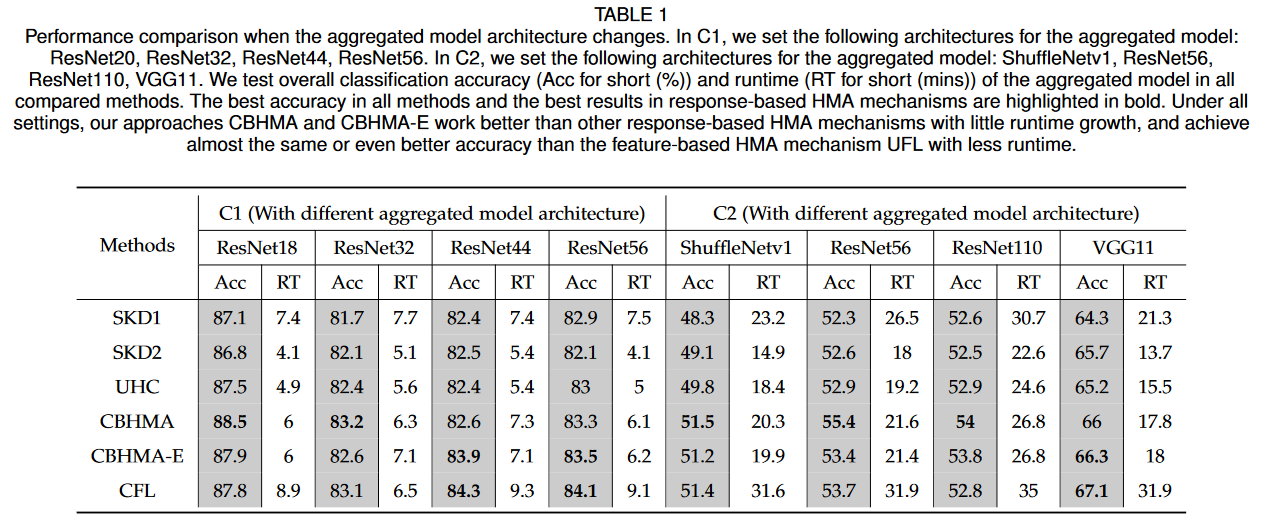
Performance comparison when the aggregated model architecture changes.
首先,我们可以观察到,在所有设置下,CBHMA和CBHMA-E始终超过SKD1,SKD2和UHC。我们可以将其解释为以下内容。 CBHMA是一种使用我们的设计从UHC修改的类平衡的HMA算法,CBHMA-E是一种通过我们的设计从SKD2修改的类平衡的HMA算法。借助我们的设计,CBHMA和CBHMA-E在训练聚合模型时对班级的监督更为重要,并解决了UHC和SKD2中的不平衡监督问题,从而提高了聚合模型的整体准确性。
其次,可以发现CBHMA和CBHMAE的性能类似,有时CBHMA的效果比CBHMA-E更好,有时还有另一种方法。它进一步证明了CBHMA的可扩展性,因为CBHMA-E是CBHMA的变体。
5. CONCLUSION
在本文中,我们提出了一种基于响应的类别的异构模型聚合机制,称为CBHMA,以处理异构模型聚合中的不平衡监督和隐私泄漏问题。它可以通过有限的响应信息来整合异构的现有模型,并产生一种综合模型,其class bias得到缓解。 CBHMA根据不平衡监督状态在基于响应的异构模型聚合算法中调整每个类的重要性,从而通过有限的响应信息将异构的设备模型整合到一个平衡的聚合模型中。
在两个现实世界数据集上进行的广泛实验表明,CBMHA可以为异构的设备模型提供更强的隐私保证,并生成比最先进机制具有更好性能的类平衡汇总模型。
P.S.开会小记:
貌似“个性化联邦学习”里面也会存在解决异构模型聚合的问题,可以看看

